
Appearance
LLM Configuration
This guide is for administrators who need to configure Large Language Models (LLMs) for Datafor AI Agent. After configuration, the Agent can use LLM-backed capabilities such as question understanding, analysis planning, query model generation, result interpretation, follow-up question generation, and semantic retrieval.
1. Open the LLM Configuration Panel
- Open the Datafor console.
- Sign in with an administrator account.
- Open AI Agent.
- Click LLM in the top toolbar.
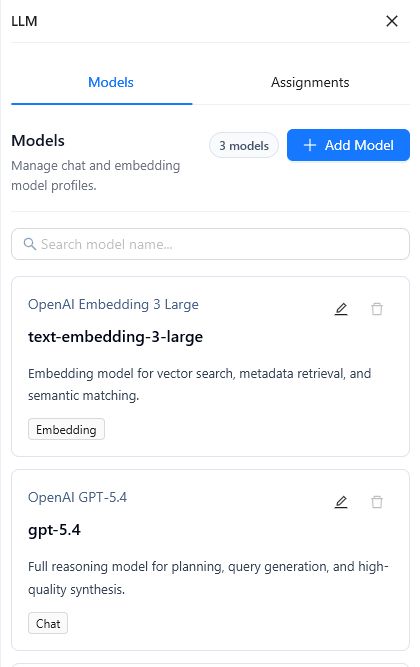
The LLM panel opens on the right side. It contains two tabs:
- Models: Manage model profiles, including model name, API endpoint, API key, quota, and cost.
- Assignments: Assign model profiles to the Agent roles that use them at runtime.
2. Prepare the Required Information
Before adding a model, prepare the following information:
- Model provider, such as OpenAI, Qwen, DeepSeek, Gemini, Anthropic, or a custom OpenAI-compatible service.
- Model name, such as
gpt-5.4-miniortext-embedding-3-large. Use the exact model ID required by the provider. - API endpoint. For OpenAI-compatible services, this is usually a base URL such as
https://api.openai.com/v1. - API key.
- Input and output token prices per 1,000,000 tokens. These values are used for Agent operations cost statistics.
- An embedding model, if you need semantic retrieval, metadata recall, or semantic matching.
3. Add a Model Profile
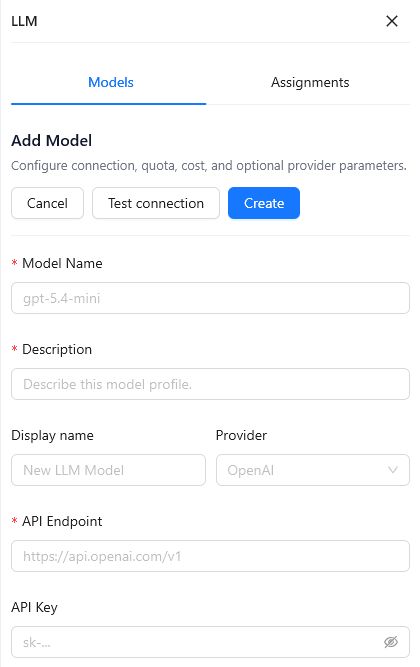
On the Models tab, click Add Model and fill in the model profile form.
Field reference:
| Field | Required | Description |
|---|---|---|
| Model Name | Yes | The provider-specific model ID. Chat models and embedding models should be created as separate profiles. |
| Description | Yes | Describes how the model should be used. It is recommended to clearly state whether the profile is for Chat or Embedding. |
| Display name | No | The name shown in the UI. It does not affect model calls. |
| Provider | No | Select OpenAI, Qwen, DeepSeek, Gemini, Anthropic, or Custom. |
| API Endpoint | Yes | The model service endpoint. OpenAI-compatible services usually use the base /v1 endpoint. |
| API Key | No | The key used to access the model service. After saving, the key is stored on the server and shown as a masked value in the UI. |
The current UI does not provide a separate Capability selector. The system infers model capability from the model name, display name, or description. A model containing embedding or embed is usually recognized as an Embedding model; otherwise, it is treated as a Chat model by default. When configuring an embedding model, include embedding or embed in the model name or description so it appears in the Embedding Model assignment list.
4. Configure Advanced Parameters, Quota, and Cost
Scroll down in the Add Model form to configure optional runtime parameters, quota, and cost.
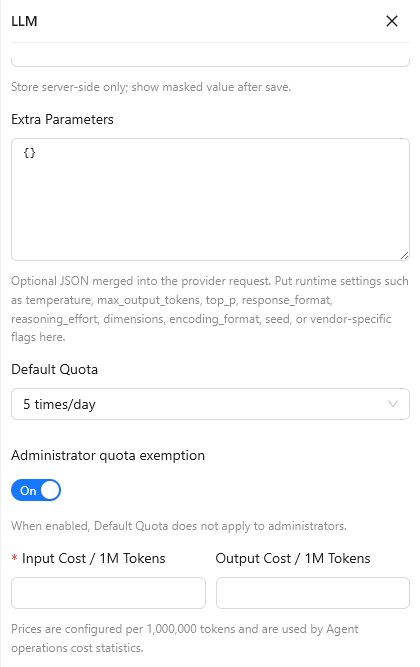
Extra Parameters accepts an optional JSON object. These values are merged into the provider request. Example:
{
"temperature": 0.1,
"max_output_tokens": 4096
}Important notes:
Extra Parameters must be a valid JSON object. Arrays and plain text are not allowed.
Do not put connection secrets or endpoint fields such as
api_key,Authorization,endpoint, orbase_urlin Extra Parameters. Use the dedicated fields instead.For OpenAI GPT-5 family Chat models, you can use
reasoningto tune reasoning effort. A common quality-sensitive setting is:{ "reasoning": { "effort": "medium" }, "max_output_tokens": 4096 }Use
lowreasoning effort for low-risk auxiliary roles,mediumfor normal production analytical roles, andhighfor complex planning or query model generation when answer quality is more important than cost or latency.The Agent requests structured JSON for structured runtime stages where required. Avoid adding provider-specific output-format parameters unless they are supported by the selected provider endpoint and have been tested.
Default Quota supports
5,10,20, or50calls per day.When Administrator quota exemption is enabled, the default quota does not apply to administrators.
Input Cost / 1M Tokens is required. Output Cost / 1M Tokens is optional. Both values are used for Agent operations cost statistics.
After filling in the form:
- Click Create to save the model profile.
- To test provider connectivity after saving, click the edit icon on the model card and then click Test connection.
In the current UI, Test connection on the new-model form mainly validates required fields and JSON format. The real backend connectivity test is available from the edit page of an already saved model. If the real test fails, check the API key, endpoint, model name, and provider compatibility parameters.
5. Assign Models to Agent Roles
After creating model profiles, open the Assignments tab. Every role must have one compatible model assigned before assignments can be saved.
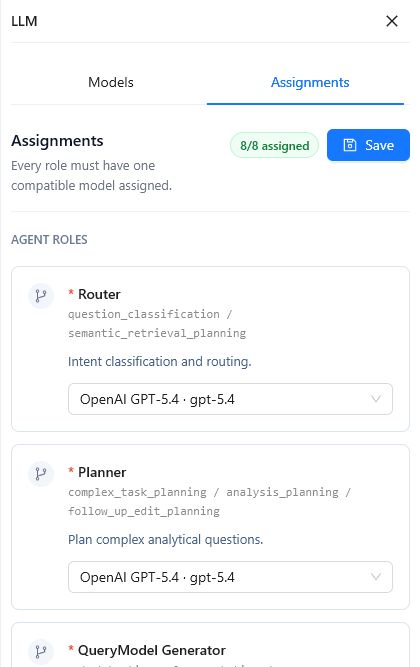
Roles are divided into two groups:
| Group | Role | Required model type | Purpose |
|---|---|---|---|
| Agent Roles | Router | Chat | Classifies questions, identifies intent, and routes requests. |
| Agent Roles | Planner | Chat | Plans complex analytical questions. |
| Agent Roles | QueryModel Generator | Chat | Generates the governed SimplifiedQueryModel. |
| Agent Roles | Query Repair | Chat | Reserved for future query repair stages. |
| Agent Roles | Answer Writer | Chat | Explains query results, dashboard insights, visualization recommendations, and complex analysis synthesis. |
| Agent Roles | Follow-up Generator | Chat | Generates follow-up questions and alternative analysis suggestions. |
| Agent Roles | Reference Evaluator | Chat | Reserved for offline or manual evaluation. |
| System Roles | Embedding Model | Embedding | Used for vector search, metadata retrieval, and semantic matching. |
Recommended setup:
- For an initial setup, assign all Agent Roles to one stable Chat model to reduce configuration complexity.
- For quality-sensitive roles such as Planner, QueryModel Generator, and Answer Writer, use a stronger Chat model.
- For cost-sensitive or latency-sensitive roles such as Router and Follow-up Generator, you may switch to a lighter Chat model after validating quality.
- Embedding Model must use an Embedding model. It cannot use a regular Chat model.
OpenAI quality-first recommendation
If you use OpenAI and answer quality is the primary goal, use separate model profiles by Agent role instead of assigning every role to the cheapest Chat model. The highest-risk stages are complex planning and governed query model generation; if they fail, the final answer is unlikely to be correct even if the answer-writing model is strong.
Recommended OpenAI role assignment:
| Role | Recommended OpenAI model | Suggested reasoning effort | Why |
|---|---|---|---|
| Router | gpt-5.4-mini | low or medium | Handles question classification and retrieval planning. It is important, but the output is small and later stages can still guard or clarify. Upgrade to gpt-5.4 if multilingual or ambiguous routing quality is not good enough. |
| Planner | gpt-5.5 | medium, or high for complex tenants | Plans bounded complex analytical workflows. Use the strongest model here because planning errors affect every downstream step. |
| QueryModel Generator | gpt-5.5 | medium, or high for noisy metadata | Generates the governed SimplifiedQueryModel. This is the most quality-critical runtime role because it must preserve requested metrics, dimensions, filters, time ranges, rankings, and comparisons. |
| Query Repair | gpt-5.5 | medium | Reserved for future query repair stages. If enabled, keep it at the same quality tier as QueryModel Generator. |
| Answer Writer | gpt-5.4 | medium | Explains query results, dashboard insights, visualization recommendations, and complex synthesis. gpt-5.4 is the recommended balance of answer quality, cost, and latency. Use gpt-5.5 if complex final synthesis or executive-quality insight is the top priority. |
| Follow-up Generator | gpt-5.4-mini | low | Generates follow-up questions and alternative analysis suggestions. This role is lower risk than query generation or final synthesis, so a smaller model is usually enough. |
| Reference Evaluator | gpt-5.5 | high or xhigh | Reserved for offline or manual evaluation. Prefer maximum evaluation quality over runtime cost. |
| Embedding Model | OpenAI embedding model, for example text-embedding-3-large for quality-sensitive retrieval | Not applicable | Embedding is not a Chat role. Use a stronger embedding model when semantic recall quality is important; use a smaller embedding model only after retrieval-quality validation. |
For a production setup with a good balance of quality, cost, and latency, create three Chat model profiles:
| Profile | Model | Assign to |
|---|---|---|
| OpenAI Quality | gpt-5.5 | Planner, QueryModel Generator, Query Repair, Reference Evaluator |
| OpenAI Balanced | gpt-5.4 | Answer Writer |
| OpenAI Fast | gpt-5.4-mini | Router, Follow-up Generator |
Avoid using an ultra-small model such as gpt-5.4-nano for core analytical roles when answer quality is the first priority. It can be considered for very high-volume, low-risk suggestion generation only after validating that follow-up quality remains acceptable. OpenAI model availability, pricing, and recommended replacements can change over time, so verify the exact model IDs and prices in OpenAI's current model documentation before production rollout.
When every role is assigned, click Save.
6. Verify That the Configuration Works
After saving, run a basic validation:
- Go back to New Chat.
- Select an analysis model.
- Ask a simple analytical question, such as a monthly trend for a metric.
- Confirm that the Agent can understand the question, run the query, and return an interpreted result.
If the Agent reports that the LLM is unavailable, the connection failed, authentication failed, or roles are not configured, return to the LLM panel and check both the model profiles and role assignments.
7. Troubleshooting
| Problem | How to fix it |
|---|---|
| Creating a model fails | Check that Model Name, Description, API Endpoint, and Input Cost / 1M Tokens are filled in, and that Extra Parameters is a valid JSON object. |
| Assignments cannot be saved | Every role must have a model assigned. Agent Roles require Chat models, and Embedding Model requires an Embedding model. |
| A new embedding model does not appear in the Embedding dropdown | Check whether the model name, display name, or description contains embedding or embed. The current UI uses these terms to infer model capability. |
| The delete button is disabled | The model is currently assigned to one or more roles. Reassign those roles to another model, save the assignments, and then delete the model. |
| The API key is not visible after saving | This is expected. The key is stored on the server and shown as a masked value. To replace it, edit the model and enter a new key. |
| Connection test returns 401 or 403 | The API key is usually invalid, lacks permission, or the provider account is not available. |
| Connection test returns 400 or 404 | The endpoint, model name, API mode, or provider compatibility parameter is usually incorrect. |
| Connection test times out | Check network connectivity from the server to the model provider, including firewall and proxy settings. |
8. Security Recommendations
- Only administrators should maintain model profiles and role assignments.
- Do not put API keys in Extra Parameters, screenshots, support tickets, or ordinary chat messages.
- After changing provider, model name, or endpoint, run the connection test again and validate the Agent with a simple analytical question.
- In production, use clear descriptions for Chat and Embedding model profiles so that auditing, troubleshooting, and cost analysis are easier.